Residual
Contents
Residual¶
This example shows a CSL program that uses a rectangle of 2-by-2 PEs to compute
|b - A * x|, i.e., the norm of the residual b - A * x.
A is an M x N matrix. Each PE computes a part of the A'*x
multiplication, where A''' is a ``M/2 x N/2 matrix. In other words, each PE
essentially does “a fourth” of the multiplication. It then does a row reduction,
so that the last column of PEs has the result b - A*x. Finally, the PEs of
the last column computes the norm, |b-A*x|, via a column reduction.
The 2-by-2 rectangle is surrounded by memcpy infrastructure which occupies five column of PEs shown below. The memcpy routes the input and output data between the host and the device.
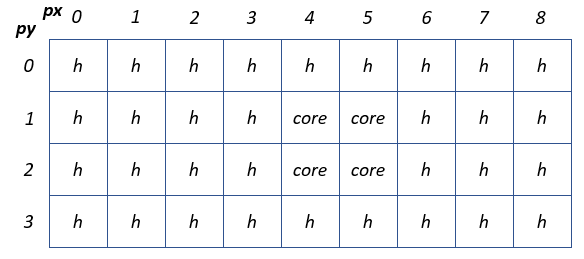
The matrix A, the input vectors x and b and the output scalar (the
computed norm |b - A * x|) are supported by memcpy streaming.
The matrix
Ais distributed into the PEs. For simplicity, the matrix dimensionsM x Nare assumed even.The vector
xis distributed into the first row PEs. The first row receivesxfrom the memcpy, then broadcastsxinto other rows. The incoming vectorxis distributed across all N = 4 PEs along the top side of the rectangle.The vector
bis distributed into rows of the first column. The vectorbis distributed across all M = 6 PEs along the left side of the rectangle.The scalar
nrm_ris sent out by the PE with coordinatespe_x=1andpe_y=0.
Three functions GEMV, AXPY, and NRMINF are defined separately, and
are loaded by import_module. GEM computes y = A*x, AXPY
computes y = alpha*x and NRMINF computes the norm. SIMD operations
are used in GEMV and AXPY to reduce the overhead of address computation.
layout.csl¶
// This example computes |b-A*x|_inf on a 2-by-2 rectangle which has P0.0, P0.1, P1.0 and P1.1
// The matrix A is distributed to every PE via memcpy
// The vector x is distributed to first row PEs via memcpy
// The vector b is distributed to first column PEs via memcpy
// P1.0 sends out the result |b-A*x| via memcpy
//
// Each PE receives the vector x and computes A*x locally, then performs a row reduction to finish y = b - A*x
// The last column contains the vector y, and performs a column reduction to obtain |b-A*x|
//
// internal color PSUM is used in row reduction
// internal color NRM is used in column reduction
// (LOCAL_OUT_SZ, LOCAL_IN_SZ) is the dimension of local tensor
// A is LOCAL_OUT_SZ-by-LOCAL_IN_SZ
// x is LOCAL_IN_SZ-by-1
// y is LOCAL_OUT_SZ-by-1
//
// The unit test sets up the parameters LOCAL_OUT_SZ and LOCAL_IN_SZ via cslc
// LOCAL_OUT_SZ = M / height
// LOCAL_IN_SZ = N / width
// where M, N are dimensions of global tensors A_global, x_global and y_global
// A_global is M-by-N
// x_global is N-by-1
// y_global is M-by-1
param LOCAL_OUT_SZ: i16;
param LOCAL_IN_SZ: i16;
param width: i16;
param height: i16;
// Colors
const RXACT_X: color = @get_color(8); // receive x
const PSUM: color = @get_color(9); // row reduction
const NRM: color = @get_color(10); // column reduction
const memcpy = @import_module("<memcpy/get_params>", .{
.width = width,
.height = height
});
layout {
@comptime_assert(2 == width);
@comptime_assert(2 == height);
// step 1: configure the rectangle which does not include halo
@set_rectangle(width, height);
// step 2: compile csl code for a set of PEx.y and generate out_x_y.elf
// format: @set_tile_code(x, y, code.csl, param_binding);
@set_tile_code(0, 0, "residual.csl", .{
.memcpy_params = memcpy.get_params(0),
.TXACT_X = RXACT_X,
.TXACT_Y = PSUM,
.LOCAL_OUT_SZ = LOCAL_OUT_SZ,
.LOCAL_IN_SZ = LOCAL_IN_SZ,
});
@set_tile_code(0, 1, "residual.csl", .{
.memcpy_params = memcpy.get_params(0),
.RXACT_X = RXACT_X,
.TXACT_Y = PSUM,
.LOCAL_OUT_SZ = LOCAL_OUT_SZ,
.LOCAL_IN_SZ = LOCAL_IN_SZ,
});
@set_tile_code(1, 0, "residual.csl", .{
.memcpy_params = memcpy.get_params(1),
.TXACT_X = RXACT_X,
.RXACT_Y = PSUM,
.RXACT_NRM = NRM,
.LOCAL_OUT_SZ = LOCAL_OUT_SZ,
.LOCAL_IN_SZ = LOCAL_IN_SZ,
});
@set_tile_code(1, 1, "residual.csl", .{
.memcpy_params = memcpy.get_params(1),
.RXACT_X = RXACT_X,
.RXACT_Y = PSUM,
.TXACT_NRM = NRM,
.LOCAL_OUT_SZ = LOCAL_OUT_SZ,
.LOCAL_IN_SZ = LOCAL_IN_SZ,
});
// step 3: global and internal routing
// format: @set_color_config(x, y, color, route);
// routing of RXACT_X
// - cliff distribution of x along columns
// - broadcast from the north to the south
// py = 0 receives x via H2D_2, and forwards x to south
// py = 1 receives x from north
@set_color_config(0, 0, RXACT_X, .{ .routes = .{ .rx = .{ RAMP }, .tx = .{ SOUTH }}});
@set_color_config(0, 1, RXACT_X, .{ .routes = .{ .rx = .{ NORTH }, .tx = .{ RAMP }}});
@set_color_config(1, 0, RXACT_X, .{ .routes = .{ .rx = .{ RAMP }, .tx = .{ SOUTH }}});
@set_color_config(1, 1, RXACT_X, .{ .routes = .{ .rx = .{ NORTH }, .tx = .{ RAMP }}});
// routing of PSUM (for row reduction)
// P0.0, P0.1: send partial sum
// P1.0, P1.1: receive partial sum
@set_color_config(0, 0, PSUM, .{ .routes = .{ .rx = .{ RAMP }, .tx = .{ EAST }}});
@set_color_config(0, 1, PSUM, .{ .routes = .{ .rx = .{ RAMP }, .tx = .{ EAST }}});
@set_color_config(1, 0, PSUM, .{ .routes = .{ .rx = .{ WEST }, .tx = .{ RAMP }}});
@set_color_config(1, 1, PSUM, .{ .routes = .{ .rx = .{ WEST }, .tx = .{ RAMP }}});
// routing of NRM (for column reduction)
// P1.0: receive local nrm from P1.1
// P1.1: send local nrm to P1.0
@set_color_config(1, 0, NRM, .{ .routes = .{ .rx = .{ SOUTH }, .tx = .{ RAMP }}});
@set_color_config(1, 1, NRM, .{ .routes = .{ .rx = .{ RAMP }, .tx = .{ NORTH }}});
// export symbol name
@export_name("A", [*]f32, true);
@export_name("x", [*]f32, true);
@export_name("y", [*]f32, true);
@export_name("nrm", [*]f32, true);
@export_name("bcast_x", fn()void);
}
residual.csl¶
// This example computes |b-A*x|_inf on a 2-by-2 rectangle which has P0.0, P0.1, P1.0 and P1.1
// The matrix A is distributed to every PE via memcpy
// The vector x is distributed to first row PEs via memcpy
// The vector b is distributed to first column PEs via memcpy
// P1.0 sends out the result |b-A*x| via memcpy
//
// The host sends matrix A, vector x and vector b into the core rectangle, launches a RPC to
// broadcast vector x from 1st row to other rows, computes A*x locally, then performs a row
// reduction to finish y = b - A*x.
// The last column contains the vector y and performs a column reduction to compute |b-A*x|
// Notation: a PE (Px.y) is labeled as (px = x, py = y)
param memcpy_params;
// Colors
// Not all PEs use all colors; initialize to 15, which is unused and has no routing
param RXACT_X: color = @get_color(15); // py = 0: don't care
// py > 0: receive vector x from the north
param TXACT_X: color = @get_color(15); // py = 0: send x to the south
param RXACT_Y: color = @get_color(15); // px = 0: forward b-A*x to the east
// px = 1: receive partial sum (b - A*x) from px = 0
param TXACT_Y: color = @get_color(15); // px = 0: send parital sum to px = 1
param RXACT_NRM: color = @get_color(15); // P1.0: receive nrm from P1.1
param TXACT_NRM: color = @get_color(15); // P1.1: send local nrm to P1.0
// Queue IDs
const TXACT_X_oq: output_queue = @get_output_queue(2);
const TXACT_Y_oq: output_queue = @get_output_queue(3);
const TXACT_NRM_oq: output_queue = @get_output_queue(4);
const RXACT_X_iq: input_queue = @get_input_queue(5);
const RXACT_Y_iq: input_queue = @get_input_queue(6);
const RXACT_NRM_iq: input_queue = @get_input_queue(7);
// Task IDs
const COMP: local_task_id = @get_local_task_id(12); // compute local Ax = A*x
const REDUCE: local_task_id = @get_local_task_id(13); // compute local b - A*x or local y - A*x
const DONE: local_task_id = @get_local_task_id(14); // compute |b-A*x| and send out the result
const EXIT: local_task_id = @get_local_task_id(17); // entrypoint to leave RPC
param LOCAL_OUT_SZ: i16; // dimension of submatrix A is LOCAL_OUT_SZ-by-LOCAL_IN_SZ
// dimension of subvector y is LOCAL_OUT_SZ-by-1
param LOCAL_IN_SZ: i16; // dimension of subvector x is LOCAL_IN_SZ-by-1
const sys_mod = @import_module("<memcpy/memcpy>", memcpy_params);
const fabric = @import_module("<layout>");
////////////////////////////////////////////////////////////////////////////////
// Main memory (48KB)
////////////////////////////////////////////////////////////////////////////////
// A is LOCAL_OUT_SZ-by-LOCAL_IN_SZ with lda=LOCAL_OUT_SZ
// x is LOCAL_IN_SZ-by-1
// y is LOCAL_OUT_SZ-by-1
// Assumption
// - _MAX_SIZE_X >= LOCAL_IN_SZ
// - _MAX_SIZE_Y >= LOCAL_OUT_SZ
// - _MAX_SIZE_A >= LOCAL_OUT_SZ*LOCAL_IN_SZ
const _MAX_SIZE_A = LOCAL_OUT_SZ * LOCAL_IN_SZ;
const _MAX_SIZE_X = LOCAL_IN_SZ;
const _MAX_SIZE_Y = LOCAL_OUT_SZ;
var A = @zeros([_MAX_SIZE_A]f32);
var x = @zeros([_MAX_SIZE_X]f32);
var y = @zeros([_MAX_SIZE_Y]f32);
// workspace for A*x
var Ax = @zeros([_MAX_SIZE_Y]f32);
// workspace for outer-product version of GEMV
var ws = @zeros([_MAX_SIZE_Y]f32);
var nrm = @zeros([1]f32);
var local_nrm: f32 = 0.0;
// (_px, _py) is the coordinate of region of interest, set by the function bcast_x
// which starts the computation
var _px: i16;
var _py: i16;
// WARNING: export pointers, not arrays
var ptr_A: [*]f32 = &A;
var ptr_x: [*]f32 = &x;
var ptr_y: [*]f32 = &y;
var ptr_nrm: [*]f32 = &nrm;
////////////////////////////////////////////////////////////////////////////////
// DSDs
// data-structure descriptors (DSDs), loaded into data-structure registers (DSRs) to configure DSR
// The DSDs are typically put in their own data segment that is placed right above lo-mem.?
//
// The content of a DSR is a DSD, which is a data structure stored in memory.
// A DSR is a numbered hardware register and, like a GPR, is memory mapped.
// DSRs hold DSDs. Their numbers are stored in instruction operand fields, where the DSD held by the DSR
// serves to describe the actual data operand, which is a memory or fabric tensor.
////////////////////////////////////////////////////////////////////////////////
const mem_x_buf_dsd = @get_dsd(mem1d_dsd, .{ .tensor_access = |i|{LOCAL_IN_SZ} -> x[i] });
const fab_recv_x_wdsd = @get_dsd(fabin_dsd, .{
.extent = LOCAL_IN_SZ,
.input_queue = RXACT_X_iq
});
const fab_trans_x_wdsd = @get_dsd(fabout_dsd, if (@is_arch("wse3")) .{
.extent = LOCAL_IN_SZ,
.output_queue = TXACT_X_oq
} else .{
.extent = LOCAL_IN_SZ,
.fabric_color = TXACT_X,
.output_queue = TXACT_X_oq
});
const mem_y_buf_dsd = @get_dsd(mem1d_dsd, .{ .tensor_access = |i|{LOCAL_OUT_SZ} -> y[i] });
const fab_recv_y_wdsd = @get_dsd(fabin_dsd, .{
.extent = LOCAL_OUT_SZ,
.input_queue = RXACT_Y_iq
});
const fab_trans_psum_wdsd = @get_dsd(fabout_dsd, if (@is_arch("wse3")) .{
.extent = LOCAL_OUT_SZ,
.output_queue = TXACT_Y_oq
} else .{
.extent = LOCAL_OUT_SZ,
.fabric_color = TXACT_Y,
.output_queue = TXACT_Y_oq
});
const mem_nrm_buf_dsd = @get_dsd(mem1d_dsd, .{ .tensor_access = |i|{1} -> nrm[i] });
const fab_recv_nrm_wdsd = @get_dsd(fabin_dsd, .{
.extent = 1,
.input_queue = RXACT_NRM_iq
});
// only used in P1.1, send the partial nrm to P1.0
const fab_trans_nrm_wdsd_p11 = @get_dsd(fabout_dsd, if (@is_arch("wse3")) .{
.extent = 1,
.output_queue = TXACT_NRM_oq
} else .{
.extent = 1,
.fabric_color = TXACT_NRM,
.output_queue = TXACT_NRM_oq
});
////////////////////////////////////////////////////////////////////////////////
// Tasks
////////////////////////////////////////////////////////////////////////////////
const gemv_mod = @import_module("gemv.csl", .{ .sizeA = _MAX_SIZE_A, .sizeX = _MAX_SIZE_X, .sizeY = _MAX_SIZE_Y });
const axpy_mod = @import_module("axpy.csl", .{ .sizeXY = _MAX_SIZE_Y });
const nrminf_mod = @import_module("nrminf.csl", .{ .sizeX = _MAX_SIZE_Y });
// All PEs compute local A*x after A and x are received
task f_comp() void {
// Ax = A * x + 0*y
var alpha: f32 = 1.0;
var beta: f32 = 0.0;
gemv_mod.sgemv_outer(LOCAL_OUT_SZ, LOCAL_IN_SZ, alpha, &A, LOCAL_OUT_SZ, &x, beta, &Ax, &ws);
// px = 0: receive vector b from the host
// px = 1: receive partial sum from the west
if (0 == _px) {
// y = b is ready
@activate(REDUCE);
} else {
// receive y from the west
@mov32(mem_y_buf_dsd, fab_recv_y_wdsd, .{ .async = true, .activate = f_reduce });
}
}
// px = 0: compute y=b-A*x, and forward partial sum y to the east
// px = 1: compute the norm |y_recv - A*x| and perform reduction of local norm
task f_reduce() void {
// y = b if px = 0
// = partial sum if px = 1
// Ax = local gemv
// px = 0: y = b - A*x
// px = 1: y = y_recv - A*x, where y_recv = b-A*x in px=0
var alpha: f32 = -1.0;
axpy_mod.saxpy(LOCAL_OUT_SZ, alpha, &Ax, &y);
if (0 == _px) {
// send partial sum to the east and finish (every PE must call f_exist)
@mov32(fab_trans_psum_wdsd, mem_y_buf_dsd, .{ .async = true, .activate = f_exit });
} else {
// px = 1: compute norm of local (b-A*x)
nrminf_mod.snrminf(LOCAL_OUT_SZ, &y, &local_nrm);
if (0 == _py) {
// P1.0: receive nrm from the south
// f_done will call f_exist
@mov32(mem_nrm_buf_dsd, fab_recv_nrm_wdsd, .{ .async = true, .activate = f_done });
} else {
// P1.1: send local nrm to north and finish
@fmovs(fab_trans_nrm_wdsd_p11, local_nrm);
@activate(EXIT); // every PE must call f_exist
}
}
}
// Only P1.0 triggers f_done to finish the reduction of |b-A*x|
task f_done() void {
// loc_nrm = |b - A*x| locally
// nrm[0] = partial result of |b - A*x| from south
if (nrm[0] < local_nrm) {
nrm[0] = local_nrm;
}
// nrm[0] = |b - A*x|
@activate(EXIT); // every PE must call f_exist
}
// the calling sequence
// px = 0: bcast_x --> f_comp --> f_reduce --> f_exit
// px = 1, py = 0: bcast_x --> f_comp --> f_reduce --> f_done --> f_exit
// px = 1, py = 1: bcast_x --> f_comp --> f_reduce --> f_exit
fn bcast_x() void {
_px = @as(i16, fabric.get_x_coord());
_py = @as(i16, fabric.get_y_coord());
if (0 == _py) {
// broadcast x to south PEs
@mov32(fab_trans_x_wdsd, mem_x_buf_dsd, .{ .async = true, .activate = f_comp });
} else {
// 0 < _py: receive x from north
@mov32(mem_x_buf_dsd, fab_recv_x_wdsd, .{ .async = true, .activate = f_comp });
}
}
task f_exit() void {
// the user must unblock cmd color for every PE
sys_mod.unblock_cmd_stream();
}
comptime {
@bind_local_task(f_comp, COMP);
@bind_local_task(f_reduce, REDUCE);
@bind_local_task(f_done, DONE);
@bind_local_task(f_exit, EXIT);
if (@get_int(TXACT_X) != 15) @initialize_queue(TXACT_X_oq, if (@is_arch("wse3")) .{ .color = TXACT_X } else .{});
if (@get_int(TXACT_Y) != 15) @initialize_queue(TXACT_Y_oq, if (@is_arch("wse3")) .{ .color = TXACT_Y } else .{});
if (@get_int(TXACT_NRM) != 15) @initialize_queue(TXACT_NRM_oq, if (@is_arch("wse3")) .{ .color = TXACT_NRM } else .{});
if (@get_int(RXACT_X) != 15) @initialize_queue(RXACT_X_iq, .{ .color = RXACT_X });
if (@get_int(RXACT_Y) != 15) @initialize_queue(RXACT_Y_iq, .{ .color = RXACT_Y });
if (@get_int(RXACT_NRM) != 15) @initialize_queue(RXACT_NRM_iq, .{ .color = RXACT_NRM });
@export_symbol(ptr_A, "A");
@export_symbol(ptr_x, "x");
@export_symbol(ptr_y, "y");
@export_symbol(ptr_nrm, "nrm");
@export_symbol(bcast_x);
}
gemv.csl¶
// inner-product version of GEMV
//
// http://www.netlib.org/lapack/explore-html/db/d58/sgemv_8f.html
// SGEMV - perform the matrix-vector operation
// y := alpha*A*x + beta*y
//
// @param[in] m number of rows of the matrix A
// @param[in] n number of columns of the matrix A
// @param[in] alpha scalar
// @param[in] A array of dimension (lda, n)
// @param[in] lda leading dimension of the matrix A which is column-major
// @param[in] x array of dimension n
// @param[in] beta scalar
// @param[in,out] y array of dimension m
// entry: if beta is zero, y can be NAN or INF
param sizeA: i16; // size of A, sizeA >= lda*n
param sizeX: i16; // size of x, sizeX >= n
param sizeY: i16; // size of y, sizeY >= m
fn sgemv_inner(m: i16, n: i16, alpha: f32, A: *[sizeA]f32, lda: i16,
x: *[sizeX]f32, beta: f32, y: *[sizeY]f32) void {
for (@range(i16, m)) |row| {
var dot: f32 = 0.0;
for (@range(i16, n)) |col| {
var Aij: f32 = (A.*)[row + col*lda];
var xj: f32 = (x.*)[col];
dot += Aij * xj;
}
// dot = A(row,:)*x
// WARNING: if beta is zero, y can be NAN or INF
var yi: f32 = 0.0;
if (beta != 0.0) {
yi = (y.*)[row];
}
yi = alpha*dot + beta*yi;
(y.*)[row] = yi;
}
}
// outer-product version of GEMV
//
// Ax = 0
// for col= 0:n-1
// Ax = Ax + A(:, col) * x(col)
// end
// if beta is not zero
// y = beta * y
// end
// y = y + alpha * Ax
//
// http://www.netlib.org/lapack/explore-html/db/d58/sgemv_8f.html
// SGEMV - perform the matrix-vector operation
// y := alpha*A*x + beta*y
//
// @param[in] m number of rows of the matrix A
// @param[in] n number of columns of the matrix A
// @param[in] alpha scalar
// @param[in] A array of dimension (lda, n)
// @param[in] lda leading dimension of the matrix A which is column-major
// @param[in] x array of dimension n
// @param[in] beta scalar
// @param[in,out] y array of dimension m
// entry: if beta is zero, y can be NAN or INF
// @param[in,out] ws workspace, array of dimension m
// To change the base address and the length of a DSD, csl requires a dummy DSD.
// The type here doesn't matter
const dummy = @zeros([1]i16);
// The length doesn't matter either since csl will overwrite it
const dummy_dsd = @get_dsd(mem1d_dsd, .{.tensor_access = |i|{42} -> dummy[i]});
fn sgemv_outer(m: i16, n: i16, alpha: f32, A: *[sizeA]f32, lda: i16,
x: *[sizeX]f32, beta: f32, y: *[sizeY]f32 , ws:*[sizeY]f32) void {
// bind vector Ax to a DSD
var mem_Ax_buf_dsd = @set_dsd_base_addr(dummy_dsd, ws);
mem_Ax_buf_dsd = @set_dsd_length(mem_Ax_buf_dsd, @bitcast(u16, m) );
// bind vector y to a DSD
// it is based on mem_Ax_buf_dsd, so no need to set the length again
var mem_y_buf_dsd = @set_dsd_base_addr(mem_Ax_buf_dsd, y);
// Ax = 0
@fmovs(mem_Ax_buf_dsd, 0.0);
// Ax = accumulate(A(:, col) * x(col))
for (@range(i16, n)) |col| {
var xj: f32 = (x.*)[col];
// bind vector w = A(:,col) to a DSD
// it is based on mem_Ax_buf_dsd, so no need to set the length again
var mem_w_buf_dsd = @set_dsd_base_addr(mem_Ax_buf_dsd, A);
mem_w_buf_dsd = @increment_dsd_offset(mem_w_buf_dsd, col * lda, f32);
@fmacs(mem_Ax_buf_dsd, mem_Ax_buf_dsd, mem_w_buf_dsd, xj);
}
// y = beta * y
// if beta is zero, y can be NAN or INF
if (beta != 0.0) {
@fmuls(mem_y_buf_dsd, mem_y_buf_dsd, beta);
}
// y = y + alpha * Ax
@fmacs(mem_y_buf_dsd, mem_y_buf_dsd, mem_Ax_buf_dsd, alpha);
}
axpy.csl¶
// http://www.netlib.org/lapack/explore-html/d8/daf/saxpy_8f.html
// SAXPY constant times a vector plus a vector.
// y = y + alpha*x
//
// @param[in] n number of elements of the input vectors
// @param[in] alpha scalar
// @param[in] x array of dimension n
// x[j] can be NAN or INF if alpha is zero
// @param[in,out] y array of dimension n
param sizeXY: i16; // size of x and y, sizeXY >= n
// To change the base address and the length of a DSD, csl requires a dummy DSD.
// The type here doesn't matter
const dummy = @zeros([1]i16);
// The length doesn't matter either since csl will overwrite it
const dummy_dsd = @get_dsd(mem1d_dsd, .{ .tensor_access = |i|{42} -> dummy[i] });
fn saxpy(n: i16, alpha: f32, x: *[sizeXY]f32, y: *[sizeXY]f32) void {
// bind vector x to a DSD
var mem_x_buf_dsd = @set_dsd_base_addr(dummy_dsd, x);
mem_x_buf_dsd = @set_dsd_length(mem_x_buf_dsd, @as(u16, n));
// bind vector y to DSD
// it is based on mem_x_buf_dsd, so no need to set the length again
var mem_y_buf_dsd = @set_dsd_base_addr(mem_x_buf_dsd, y);
// fast path: if alpha is zero, no need to compute
if (alpha == 0.0) {
return;
}
// y[j] = y[j] + x[j]*alpha, j = 0,1,2,...,n-1
// The SIMD fmacs replaces the following for-loop
// ========
// var row : i16 = 0;
// while(row < n) : (row +=1) {
// (y.*)[row] = (y.*)[row] + alpha * (x.*)[row];
// }
// ========
@fmacs(mem_y_buf_dsd, mem_y_buf_dsd, mem_x_buf_dsd, alpha);
}
nrminf.csl¶
// http://www.netlib.org/lapack/explore-html/d6/d12/snrm2_8f90.html
// SNRMINF returns the maximum of a vector
// SNRMINF = max(|x|)
//
// @param[in] n number of elements of the vector x
// @param[in] x array of dimension n
// @param[out] result scalar
// result = max(|x|)
param sizeX: i16; // size of x, sizeX >= n
fn snrminf(n: i16, x: *[sizeX]f32, result: *f32) void {
var nrm_r: f32 = 0.0;
for (@range(i16, n)) |row| {
var yi: f32 = (x.*)[row];
if (0.0 > yi) {
yi = -yi;
}
if (nrm_r < yi) {
nrm_r = yi;
}
}
(result.*) = nrm_r;
}
run.py¶
#!/usr/bin/env cs_python
""" Compute |b-A*x| using a 2-by-2 PE rectangle
The 2-by-2 rectangle is surrounded by a halo of size 1.
The halo is used to route the input and output data between the host and the device.
It does not impact the layout index of the kernel code.
For example, the kernel has 2-by-2 PEs, with the index P0.0, P1.0, P0.1, P1.1
in the layout/routing configuration.
The compiler generates ELFs out_0_0.elf, out_0_1.elf, out_1_0.elf and out_1_1.elf.
However the user needs global coordinate (including halo) for debugging, for example
P0.0 of the kernel is P1.1 when the user calls sdk_debug_shell to dump the trace or
landing log.
Each PE computes A*x and does a row reduction, so last column has the result b - A*x.
Then last column computes |b-A*x| via a column reduction.
To simplify the example, the dimensions M and N are assumed even.
Three functions gemv, axpy and nrminf are used to compute y=A*x, y=y+alpha*x and
|x|_inf locally.
Such functions are imported as modules via gemv.csl, axpy.csl and nrminf.csl.
The arrays A, x and y are passed into the function as pointers.
The vector x is distributed into columns. The first row receives x from the fabric,
then broadcasts x into other rows.
The vector b is distributed into rows of the first column.
P1.0 computes |b-A*x| which is sent out..
One can use the following command to check the landing log of P0.0,
sdk_debug_shell wavelet-trace --artifact_dir . --x 1 --y 1 trace
"""
import argparse
import json
import numpy as np
from cerebras.sdk.runtime.sdkruntimepybind import SdkRuntime, MemcpyDataType # pylint: disable=no-name-in-module
from cerebras.sdk.runtime.sdkruntimepybind import MemcpyOrder # pylint: disable=no-name-in-module
def main():
"""Main method to run the example code."""
parser = argparse.ArgumentParser()
parser.add_argument("--name", help="the test name")
parser.add_argument("--cmaddr", help="IP:port for CS system")
args = parser.parse_args()
# Get params from compile metadata
with open(f"{args.name}/out.json", encoding='utf-8') as json_file:
compile_data = json.load(json_file)
LOCAL_OUT_SZ = int(compile_data['params']['LOCAL_OUT_SZ'])
LOCAL_IN_SZ = int(compile_data['params']['LOCAL_IN_SZ'])
# if not, must redo the routing
width = 2
height = 2
M = LOCAL_OUT_SZ * height # number of rows of matrix A
N = LOCAL_IN_SZ * width # number of cols of matrix A
print(f"M = {M}, N = {N}, width = {width}, height = {height}")
# prepare host data and reference solution
np.random.seed(2)
A = np.arange(M*N).reshape(M, N).astype(np.float32)
x = np.arange(N).reshape(N, 1).astype(np.float32) + 100
b = np.arange(M).reshape(M, 1).astype(np.float32) + 200
# compute reference
Ax = np.matmul(A, x)
r = b - Ax
nrm_r = np.linalg.norm(r, np.inf)
print(f"nrm_r = |b - A*x| = {nrm_r}")
# prepare the simulation
memcpy_dtype = MemcpyDataType.MEMCPY_32BIT
memcpy_order = MemcpyOrder.ROW_MAJOR
runner = SdkRuntime(args.name, cmaddr=args.cmaddr)
sym_A = runner.get_id("A")
sym_x = runner.get_id("x")
sym_y = runner.get_id("y")
sym_nrm = runner.get_id("nrm")
runner.load()
runner.run()
# How to transform a 2-D tensor into a cliff distribution with
# column-major local tensor
#
# Example: w=2, h=2, A is 4-by-4 (lh-by-lw)
# A = | 0 1 2 3 |
# | 4 5 6 7 |
# | 8 9 10 11 |
# | 12 13 14 15 |
# A1 = A.reshape(2,2,2,2) of the form (h,lh,w,lw)
# A1 = | | 0 1| | 4 5| |
# | | 2 3|, | 6 7| |
# | |
# | | 8 9| |12 13| |
# | |10 11|, |14 15| |
# A2 = A1.transpose(0, 2, 3, 1) of the form (h, w, lw, lh)
# so the local tensor lh-by-lw is col-major
# A2 = | | 0 4| | 2 6| |
# | | 1 5|, | 3 7| |
# | |
# | | 8 12| |10 14| |
# | | 9 13|, |11 15| |
# A3 = A2.reshape(2,2,4)
# A3 = | 0 4 1 5 |
# | 2 6 3 7 |
# | 8 12 9 13 |
# | 10 14 11 15 |
# A3 is h-w-l
# |b-A*x| is from P1.0
# prepare A, x and b via memcpy
A1 = A.reshape(height, LOCAL_OUT_SZ, width, LOCAL_IN_SZ)
A2 = A1.transpose(0, 2, 3, 1)
A3 = A2.reshape(height, width, LOCAL_OUT_SZ*LOCAL_IN_SZ)
runner.memcpy_h2d(sym_A, A3.ravel(), 0, 0, width, height, LOCAL_OUT_SZ*LOCAL_IN_SZ,
streaming=False, data_type=memcpy_dtype,
order=memcpy_order, nonblock=False)
# x distributes to {py = 0}
runner.memcpy_h2d(sym_x, x.ravel(), 0, 0, width, 1, LOCAL_IN_SZ,
streaming=False, data_type=memcpy_dtype,
order=memcpy_order, nonblock=False)
# b distributes to {px = 0}
runner.memcpy_h2d(sym_y, b.ravel(), 0, 0, 1, height, LOCAL_OUT_SZ,
streaming=False, data_type=memcpy_dtype,
order=memcpy_order, nonblock=False)
# trigger the computation
runner.launch("bcast_x", nonblock=False)
# receive |b-A*x| from P1.0
nrm_r_cs = np.zeros(1, np.float32)
runner.memcpy_d2h(nrm_r_cs, sym_nrm, 1, 0, 1, 1, 1,
streaming=False, data_type=memcpy_dtype,
order=memcpy_order, nonblock=False)
runner.stop()
print(f"`nrm_r` from CPU:\n{nrm_r}")
print(f"`nrm_r_cs` from CS:\n{nrm_r_cs}")
dr = abs(nrm_r - nrm_r_cs[0])
print(f"|nrm_r - nrm_r_cs| = {dr}")
assert np.allclose(nrm_r, nrm_r_cs[0], 1.e-5)
print("\nSUCCESS!")
if __name__ == "__main__":
main()
commands.sh¶
#!/usr/bin/env bash
set -e
cslc ./layout.csl --arch=wse3 --fabric-dims=9,4 --fabric-offsets=4,1 \
--params=width:2,height:2 \
--params=LOCAL_OUT_SZ:3,LOCAL_IN_SZ:2 -o=out --memcpy --channels=1 \
--width-west-buf=0 --width-east-buf=0
cs_python run.py --name out